基于命令的 macOS 资源监控工具 asitop,可以监控CPU、GPU功耗
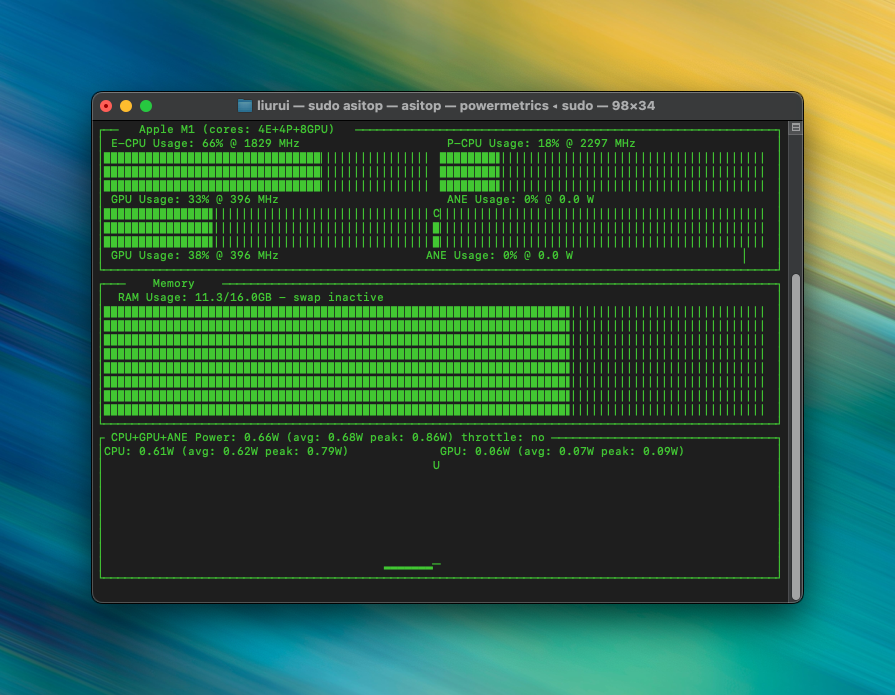
asitop 是一个用于监视 Apple Silicon Macs 性能的命令行工具,包括 CPU、GPU、ANE(Apple Neural Engine)的使用率,以及功耗和温度信息。它提供了一个实时更新的界面,可以让用户了解系统的性能状态。安装 asitop 的步骤如下:
asitop 是一个用于监视 Apple Silicon Macs 性能的命令行工具,包括 CPU、GPU、ANE(Apple Neural Engine)的使用率,以及功耗和温度信息。它提供了一个实时更新的界面,可以让用户了解系统的性能状态。安装 asitop 的步骤如下:
之前一直用CIFAR-10的数据做训练。这个数据已经内置到Keras里了,所以拉取数据很方便,只需要一行cifar10.load_data()即可。但是在实际工作中,最终肯定还是用自己的图片作为素材进行训练,所以这次决定下载Animals-10作为训练素材。
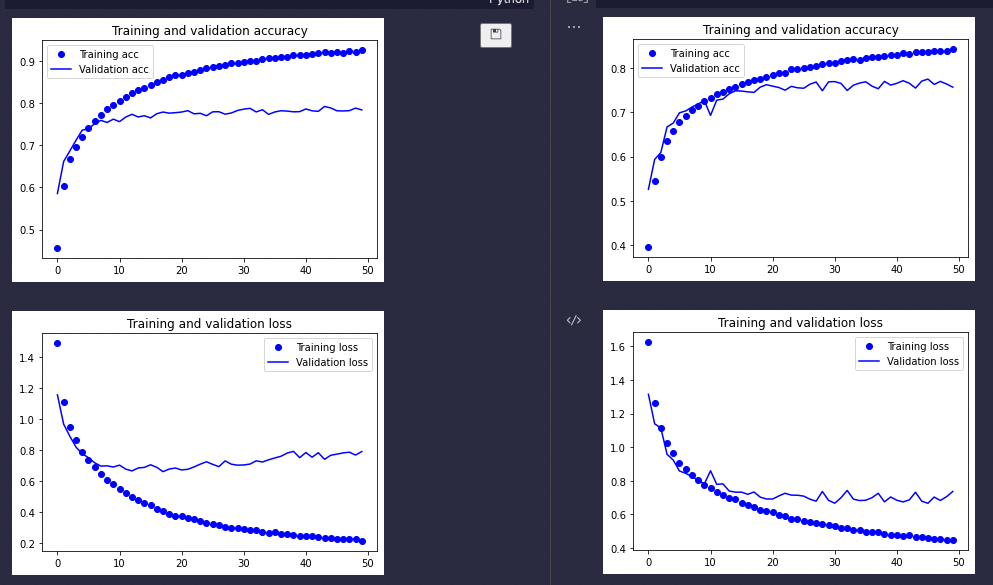
我们先来回顾一下上一次的训练结果:
可以看到在训练不到20批的时候,训练精度就与测试精度分道扬镳了。这算是一种过拟合。目前我们手上的工具箱也就剩数据增强还没用了。理论上数据增强可以弥补训练集太小的问题,从而缓解过拟合的现象。实话说,在实际操作中,这种方法已经被检验过有效了。但是总给人一种用一种机器去欺骗另一种机器的感觉,我个人觉得,机械化的数据增强应该早晚被更优秀的训练模型所取代。
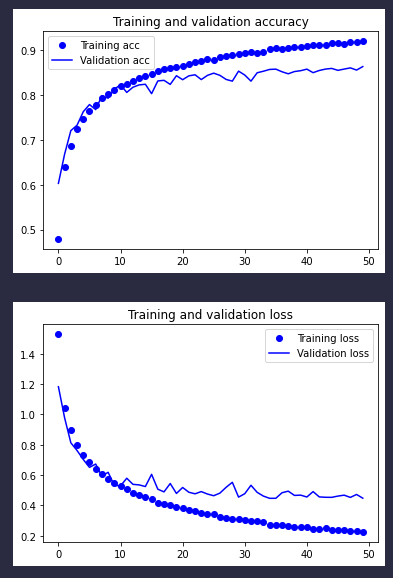
在不借助数据增强的情况下,我们已经一路把验证精度从70%多提升到了80%的水平,今天,我们借助BatchNormalization可以进一步把精度提升到超过85%。话不多说,先看结果:
在苹果M1系列芯片上运行tensorflow是可以通过插件tensorflow-metal进行GPU训练加速的,并且随着操作系统的升级以及插件的不断完善,M1的训练性能正在稳步提高,这也是苹果官方推荐的做法。
这次继续,在原来网络的基础上,加深了卷积层的数量,从原来的3层卷积,加深到了6层。核心代码如下:
model = models.Sequential() |
之前用VGG16训练了一次CIFAR10数据集,我还说用VGG16会有一个不错的起点呢,毕竟是业界训练好的模型嘛。结果今天用自建的卷积神经网络一测,结果出乎意料,自建的神经网络虽然训练精度的上升没有之前的快,但是验证精度也能达到75%的水平,跟上次区别不大。同时,虽然这次迭代次数有增加,但是得益于模型简化了许多,训练速度也提升了不少。话不多说,上结果:
今天有被windows给坑了一把,有个几个进程死活结束不掉,还遇到提示:“没有此任务的实例在运行”,所以做个笔记。
以名称为xxx.exe、PID为1024为例,正常来说,杀掉一个进程命令如下:
taskkill /F /PID 1024 |